Hiring is the only major business process that runs at a 50% failure rate and gets accepted as normal. Companies globally lose around $400 billion a year to bad hires. The interview format itself — high-pressure, conversational, 1:1 — is well documented in occupational psychology research as a poor predictor of on-the-job performance. It selects for one thing: the ability to interview.
The candidates who lose are the ones whose strengths don’t show up in a 45-minute conversation under pressure. Introverts. Anxious candidates. Neurodivergent candidates. Anyone who needs more than one channel to demonstrate what they can actually do. That’s roughly half the population, screened out before the work has even started.
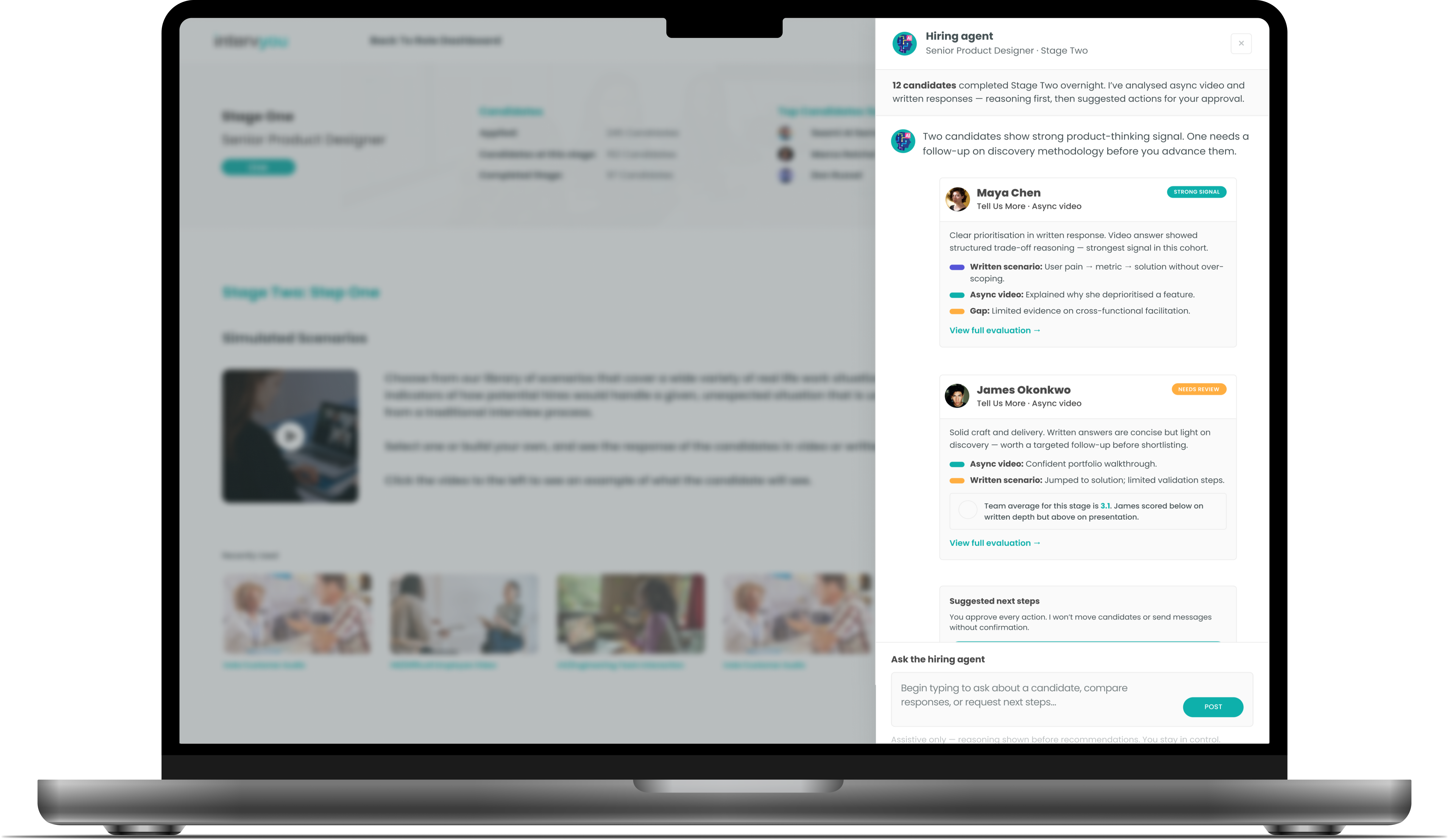
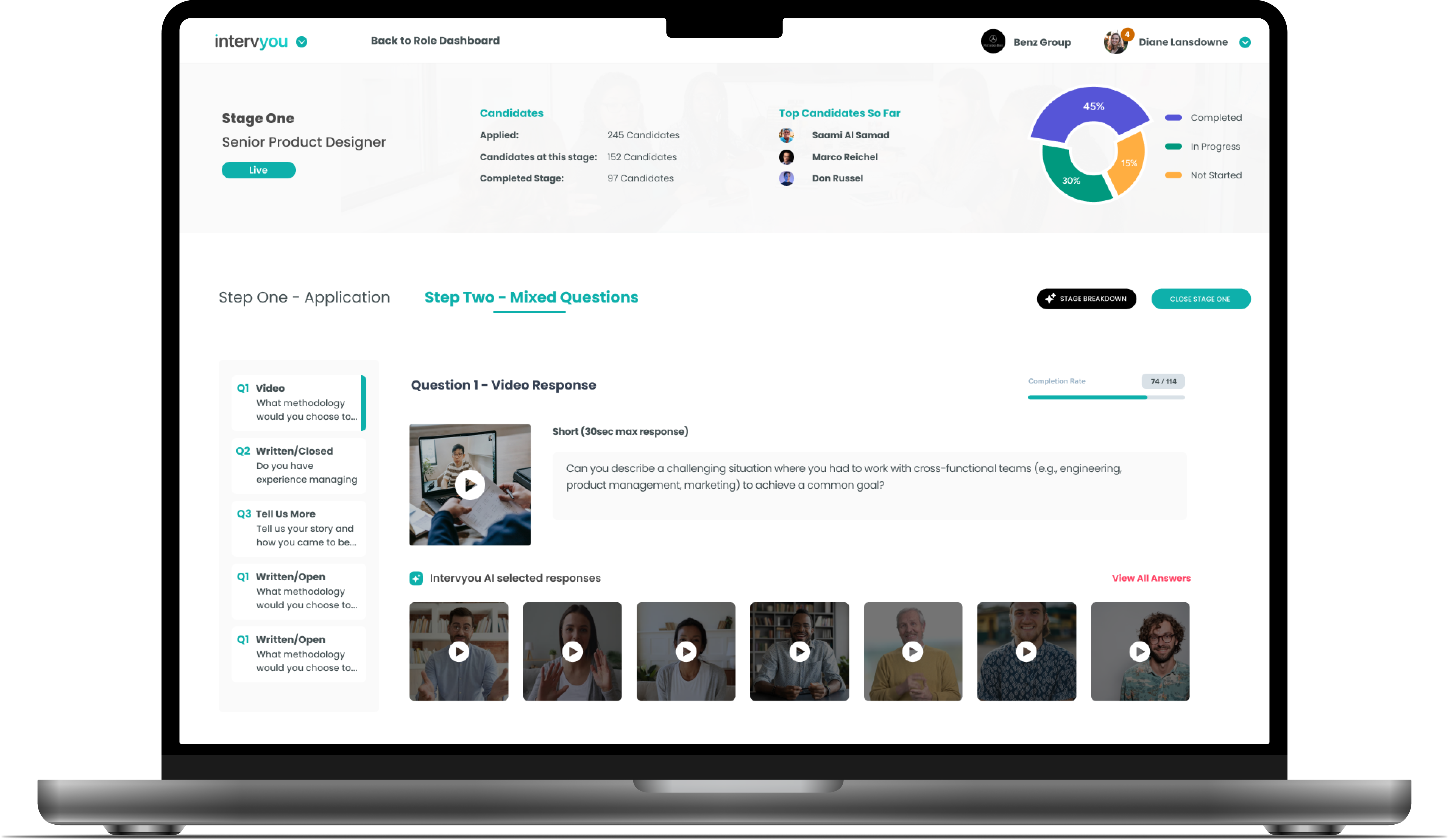
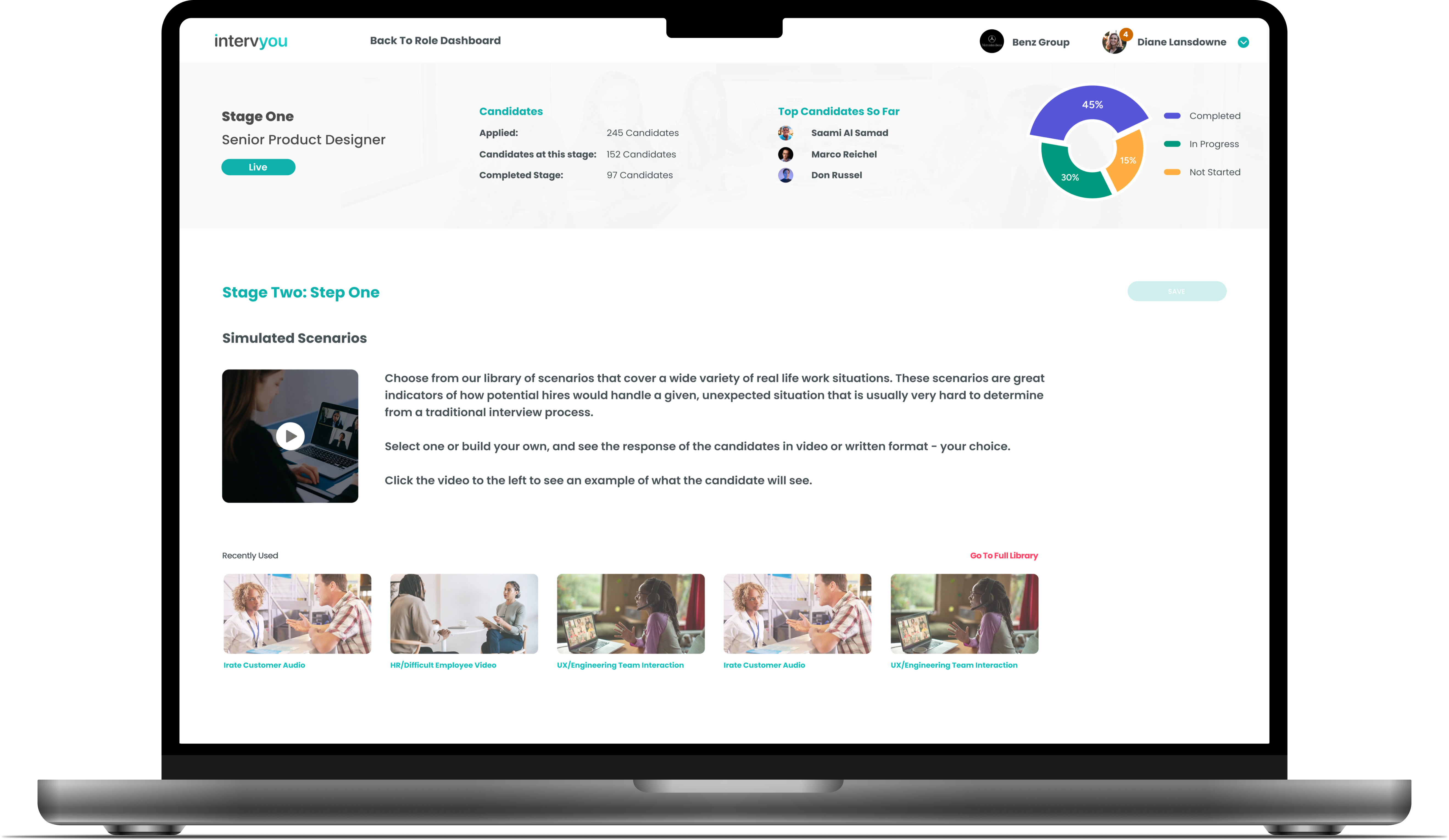
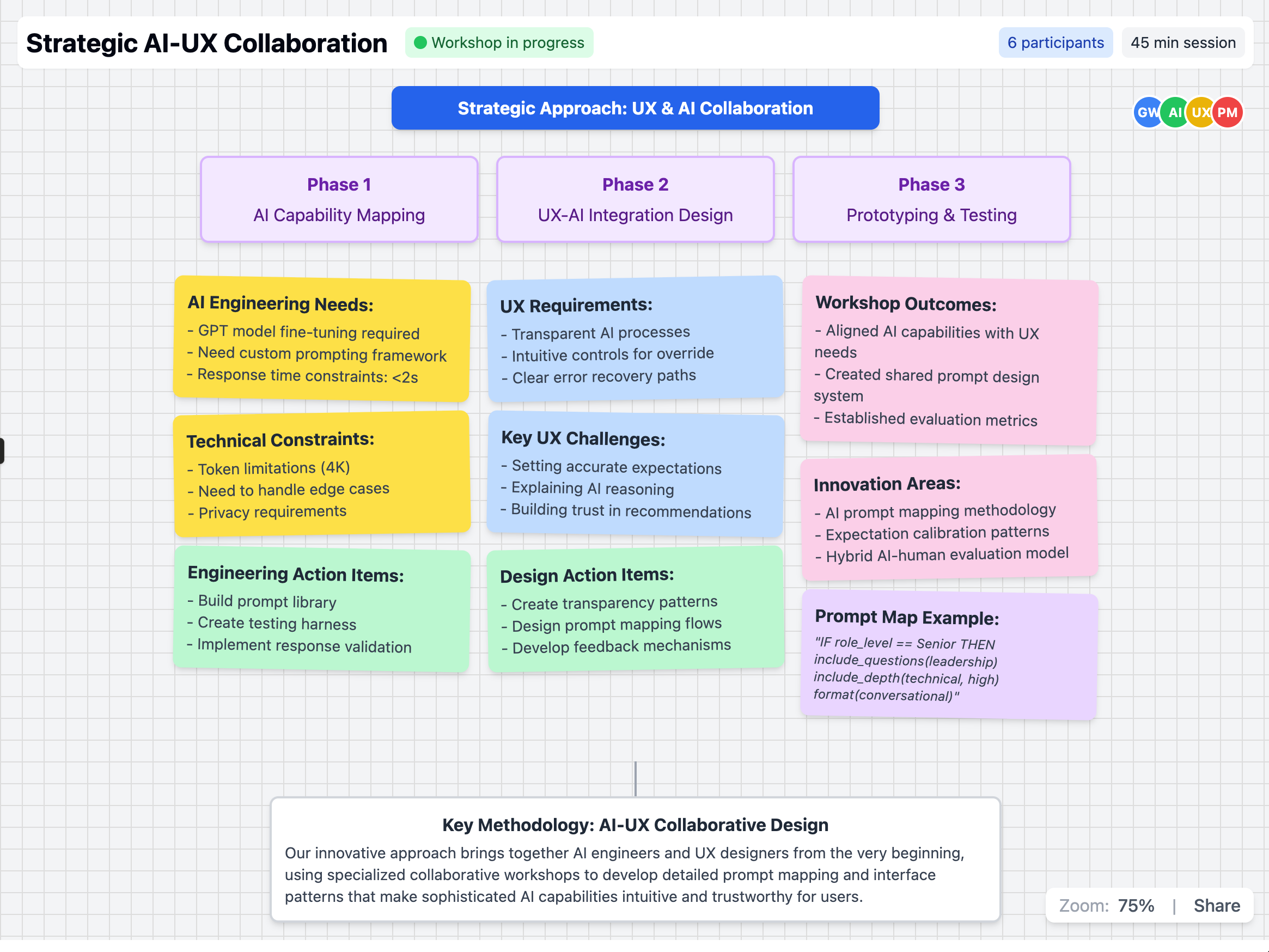
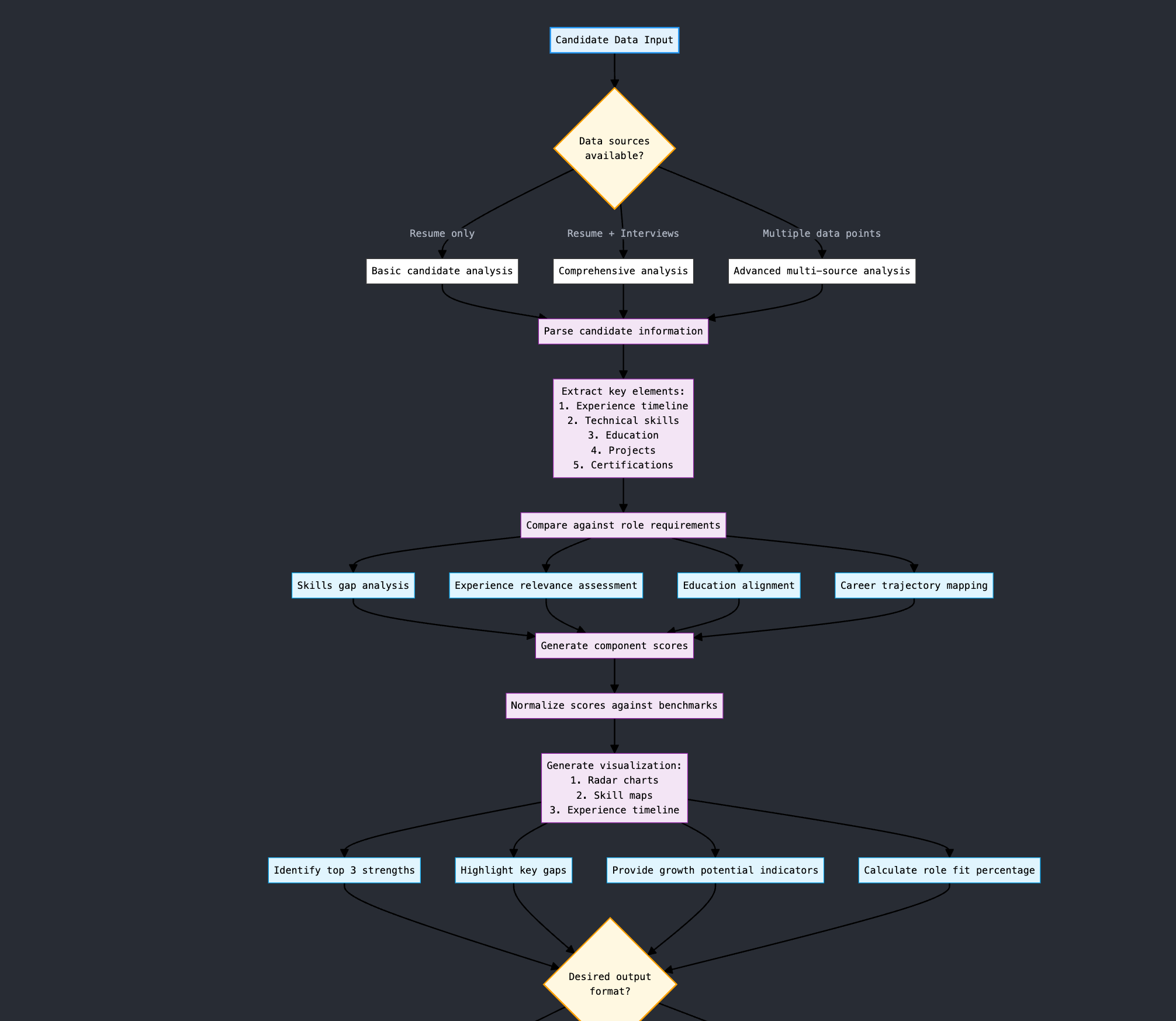
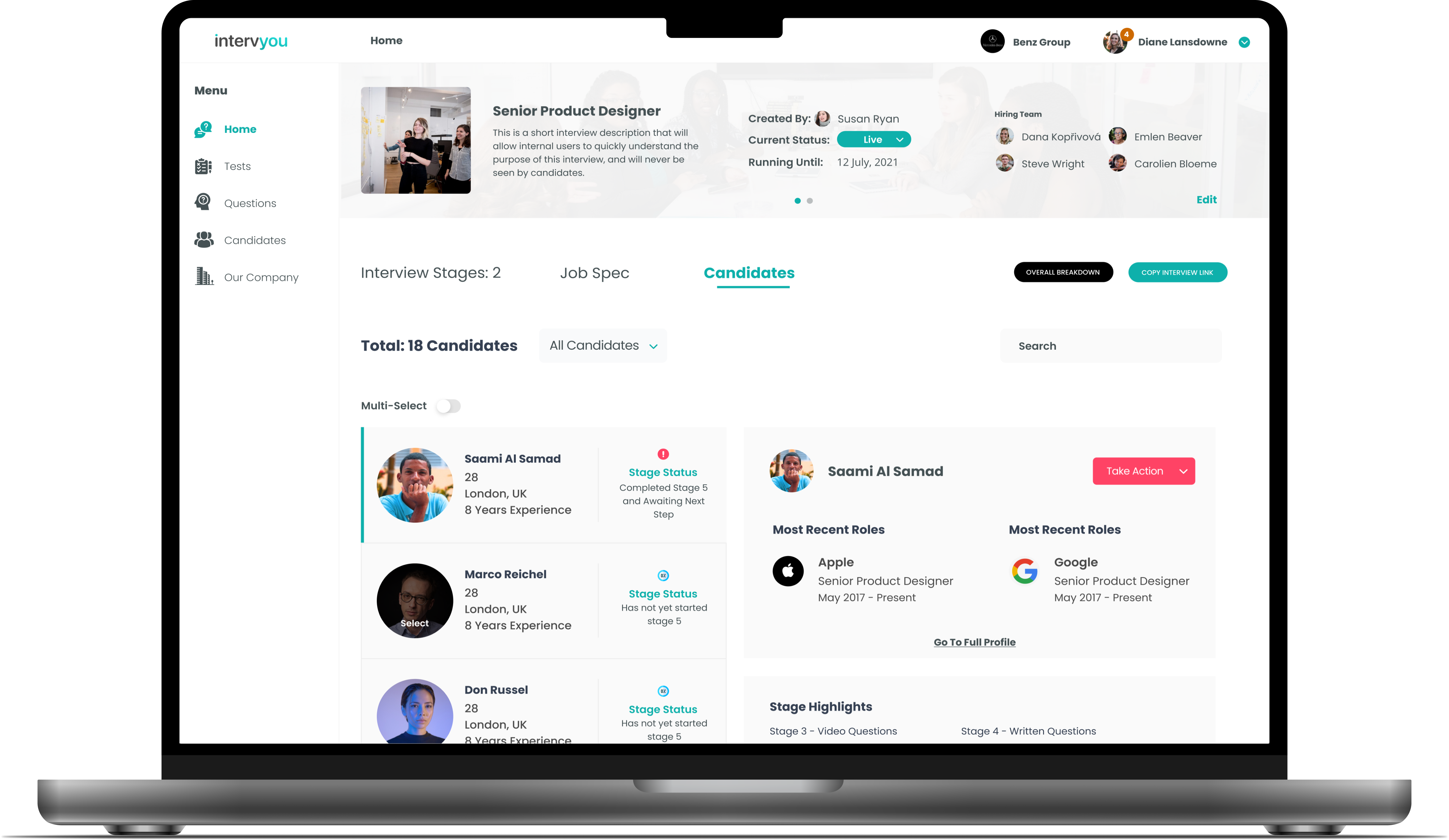
The product brief was clear: build a hiring platform that uses AI to fix this. The design brief was much harder. AI wasn’t a single feature — it had to be woven through role creation, candidate scoring, interview question generation, async video evaluation, and an AI-led interview experience itself. And in 2023, when we started, established UX patterns for AI at that depth simply did not exist.
When the technology has no precedents, what is your design process for deciding how it should behave?